Architecture
Kubernetes
Kubernetes, often abbreviated as K8s, is an open-source container orchestration platform that automates the deployment, scaling, management, and monitoring of containerized applications. It was originally developed by Google and is now maintained by the Cloud Native Computing Foundation (CNCF). Kubernetes has gained widespread adoption in the world of modern software development and is a cornerstone of cloud-native application architecture.
Kubernetes works by providing a platform for automating the deployment, scaling, management, and orchestration of containerized applications. It does this by grouping containers into logical units called "pods" and managing these pods across a cluster of machines. Kubernetes constantly monitors the desired state of the applications through declarative configuration files and takes actions to ensure that the actual state matches the desired state. It allocates resources, schedules containers to run on available nodes, load-balances traffic, and handles scaling and self-healing, making it easier to develop and maintain resilient and scalable applications in a containerized environment.
Kubernetes Job
A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate. As pods successfully complete, the Job tracks the successful completions. When a specified number of successful completions is reached, the task (ie, Job) is complete. Deleting a Job will clean up the Pods it created. Suspending a Job will delete its active Pods until the Job is resumed again.
You can also use a Job to run multiple Pods in parallel.
Fine Parallel Processing Using a Work Queue
We could run a Kubernetes Job with multiple parallel worker processes in a given pod. In this setup, as each pod is created, it picks up one unit of work from a task queue, processes it, and repeats until the end of the queue is reached.
Here is an overview of the steps in this architecture:
Start a storage service to hold the work queue: In this case, we use Redis to store our work items. A Redis custom work-queue client library is employed because Advanced Message Queuing Protocol (AMQP) does not provide a good way for clients to detect when a finite-length work queue is empty. We set up a store (such as Redis) once and reuse it for the work queues of many jobs, and other things.
Create a queue: Fill it with messages. Each message represents one task to be done.
Start a Job(s): that works on tasks from the queue. The Job starts several pods. Each pod takes one task from the message queue, processes it, and repeats until the end of the queue is reached.
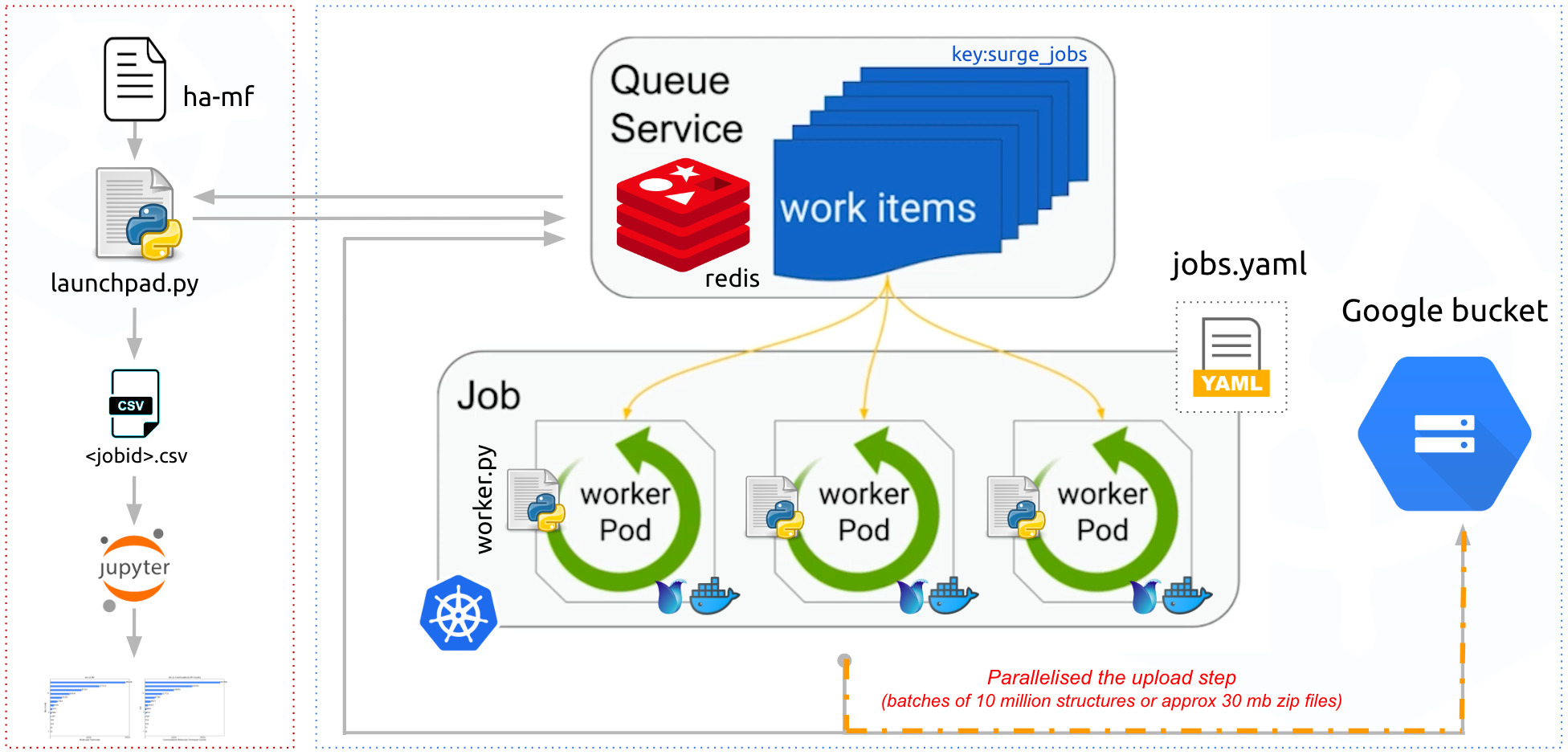
To begin the process in the Kubernetes cluster, a list of molecular formulae is created for a given heavy atom count. CDK is used to generate these formulae. The next step is to queue these formulae for a worker to execute Surge and generate chemical graph enumerations.
As mentioned, Redis is utilized as the queue service, with the tasks being filled with the instructions to use Surge for enumerating all possible chemical graphs for a specific molecular formula.
The launchpad.py, with its Redis client, populates the queue with the list of molecular formulae (and unique job_id) ready to be processed by the workers.
The workers in the pod are run until there is no formula left in the queue service. The jobs’ output files (10 million structures in each file ~ 30Mb zip files) are stored in the Google bucket. The start and end times of the Surge run and the file upload time are tracked in the Redis key-value store. The output SMI file sizes are also stored in the output files for each molecular formula.